深入洞察业务:产品卖出去,营销有成效
更新: 3/9/2026 字数: 0 字 时长: 0 分钟
真正的高级方法
所谓的“高级”,人们有两种理解。
- 形式上的高级:被少数“高人”掌握,秘不外传,讳莫如深。
- 结果上的高级:能帮助大量“菜鸟”提升效率,因为其操作简单。
比如开车上路,使用导航软件在形式上并不高级,但实现的效果确实很高级。数据分析和导航软件非常相似,通过下表的对比,可以看出,两者都是基于大量的、基础的、看似简单的工作,最后输出一个能提升效率的结果。
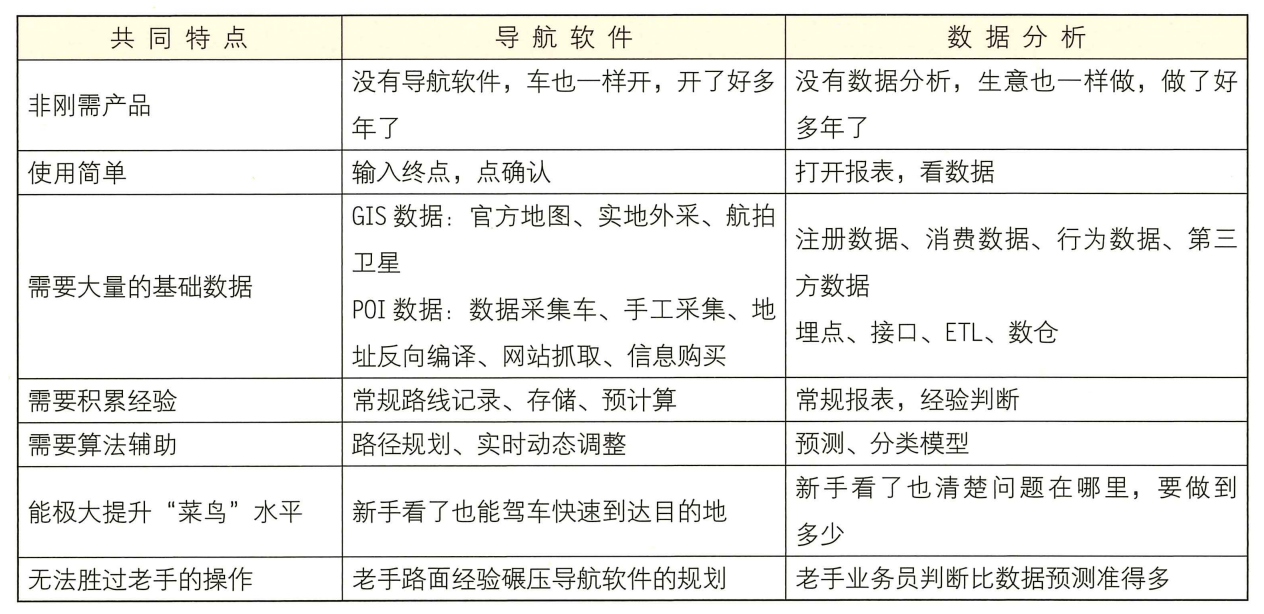
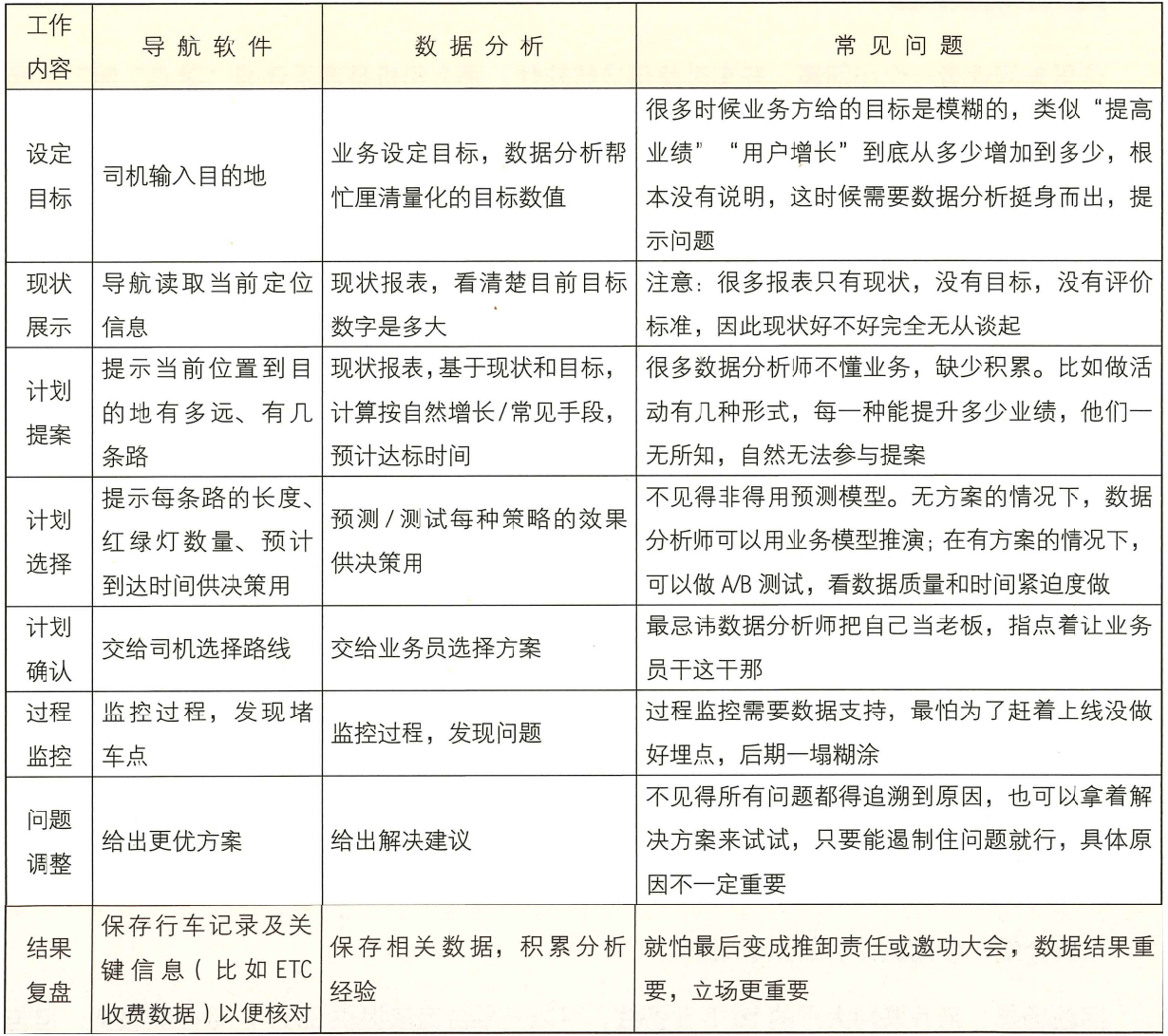
两者解决问题的手段也是类似的,如下表所示。
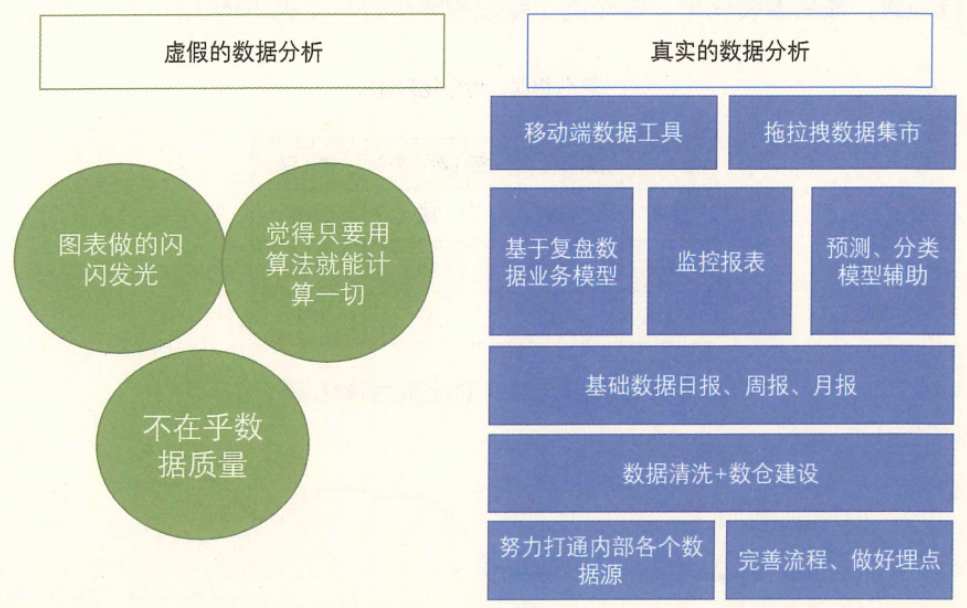
真正高级的数据分析,是体系化作战,以业务流程为保障、以数据采集为基础、以报表为骨干、以数据产品为卖点,兼有业务经验沉淀与模型辅助,是一套简单易用的工具体系,如下图所示。
可是,为什么不理解这些工作的人那么多呢?因为这些工作大部分是脚踏实地的基础工作,不会出现在外行人眼中。甚至越高级的数据分析,在外行人眼中越单!
当你试图给外行人解释:“获得数据很困难!需要打通n个系统,做n多个埋点,采集n多条数据,进行n次反复的实验……”外行人是听不懂的。因为外行人不懂这些系统流程在他们眼中数据就是阿拉伯数字,他们认为这并不复杂。
就像跟外行人解释:“导航软件需要卫星遥感、街道实拍、预计算路径……工作很复杂。他们既听不懂,也不觉得高级。在外行人眼中:"导航软件不就是导入地图,然后输入一个地址吗?有什么难的?”总之,在外行人眼里,操作简单就是方法简单,只要听懂名字就等于理解了过程。外行人普遍认为:过程听不懂且效果惊人的操作,这才叫高级。
- 如果你是业务员或老板,请给予商业分析师足够的支持和理解。
- 如果你是商业分析的从业人员,请坚定地走正确的道路,不要指望旁门左道
那么这些基础工作,如何变成一份高级数据分析的成果呢?
如何实现高级分析
1.高级分析案例
下面介绍一个高级分析的简单案例。
问题场景:某互联网大厂的toB业务线,可以向平台商家提供SaaS/Paas类服务,但苦于销售员水平不高,沟通话术质量不佳,导致转化率不足。现计划进行话术培训,提升客户转化率。
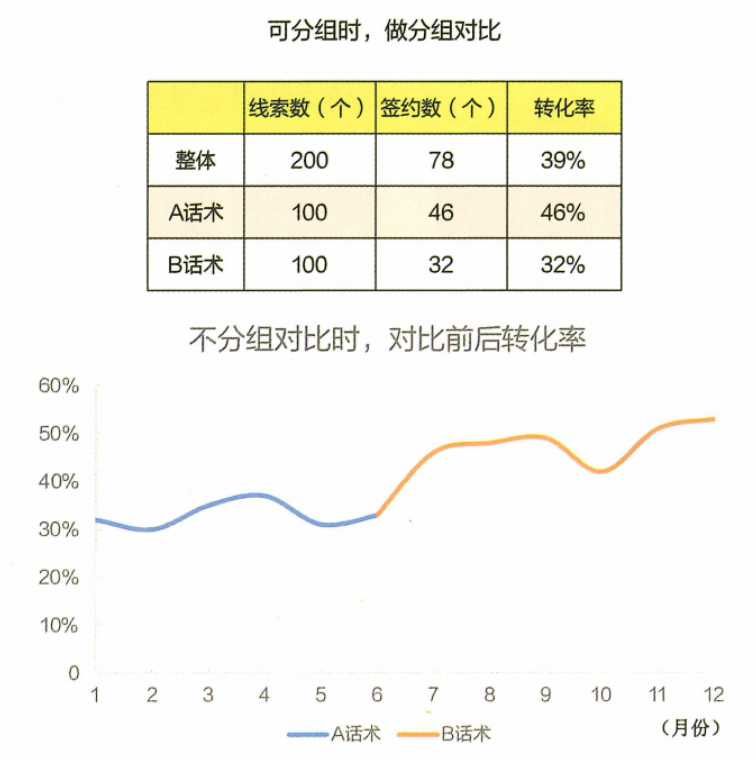
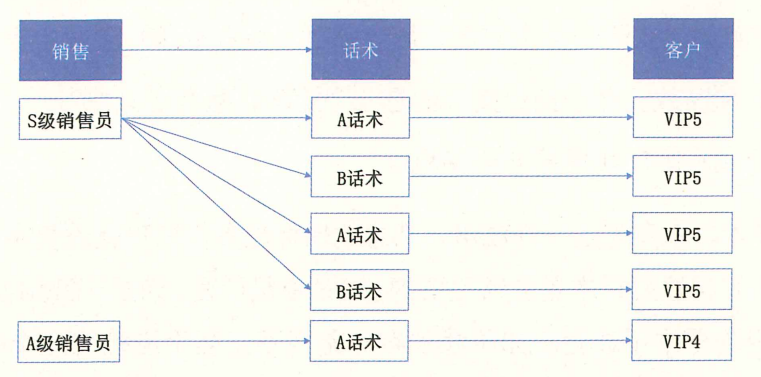
最简单的做法是定义两个版本的话术:A话术和B话术。让销售员采用这两个版本的话术与客户进行沟通,最后看转化率,哪个高了就说明哪个好!(见下图)。
这么做存在什么问题呢?至少存在以下3个方面的问题。
- 问题1:未考虑销售员本身的影响。有可能销售员本身能力强,所以才卖得好,并非话术影响。因此,需要针对不同层级的销售员,比如S级、A级、B级、C级,单独分析话术效果。
- 问题2:未考虑客户的影响。有可能特定客户就是容易成交,并非话术影响,因此需要区分客户等级,比如 VIP1、VIP2、VIP3级别客户,分别看效果。
- 问题3:未考虑话术实际影响大小。可能有的客户不受销售员的话术影响,只关心产品;有的客户则不管销售员说什么都没用,只关心价格。因此要做交叉测试,找到能受话术影响的客群,如下图所示。
在设计交叉实验的时候,要注意控制实验复杂度。比如可以根据业务实际发生的频率,排除样本情况(比如C级销售服务高级的VIP4客户的情况),还可以精简分类维度,聚焦最核心的客户等级、行业等,不用一次照顾所有情况。如果不控制复杂度,很容易会因为实验太过复杂,导致销售员抵触,最后无功而返。
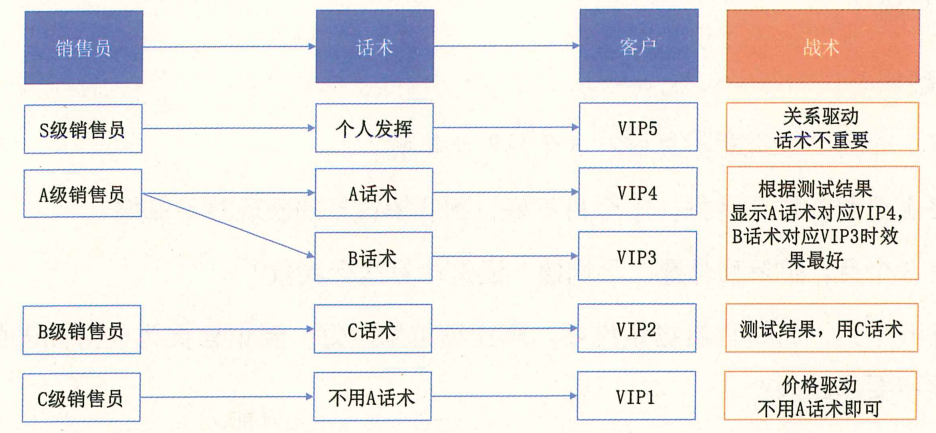
最后,得到的结果可能如下图所示,为每一类销售、每一种客户配置合理的话术,最大化产出。注意:作为测试结果,不见得非得是从A话术和B话术中二选一,很有可能发现以下问题。
- 情况1:话术根本不重要。
- 情况2:A话术和B话术都不行,需要C话术。
- 情况3:不讲xx就不会出问题。
这些都是有用的测试反馈。
看起来,这样的分析已经很高级、很有用了。然而,这样的分析需要哪些技术的支持呢?
2.技术支持之一:基础数据分类
问个简单的问题:销售员的分级(S、A、B、C级别)是怎么来的?这些分级都是基础数据分析的成果。既然有分级,那么就得有判定标准,而构建判定标准本身又是一个“大工程”
- 业绩表现好的,就是好的销售员吗?
- 意向、签约、回款、复购,哪个方面能证明他是一名好的销售员?
意向、签约、回款、复购这 4个方面,每个都至少有数量和金额两个指标。
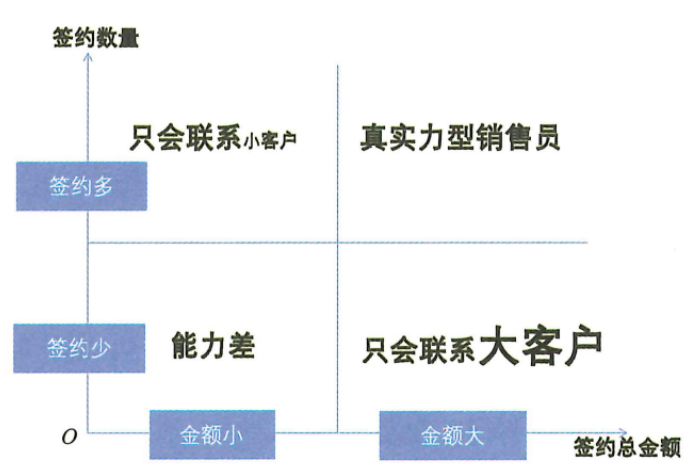
- 如果选签约和回款,两个指标交叉就是一个矩阵,怎么定义好?
- 如果是3个指标呢?如果是4个指标呢?
如何标注好样本,本身就是一件难事,考虑的指标越多,情况就越复杂(见下图,两个指标就有4种情况了),标注好样本是非常重要的。对销售员而言,如果一开始找的榜样就不够好,那么其总结出的经验根本不靠谱;如果找的客户是用不正当手段签约订单的,那找到了也没法复制,所以分级本身需要单独有专题分析。
以上所有问题,都得有一番纠结才有产出。现在简化问题,假设就考察签约金额,签约金额高的就是好的销售员。那么,又有新的问题:“考察多长时间内的表现呢?”一加入时间维度新的纠结又开始了。
新的问题如下:
- 考察1个月的表现算不算好?3个月?半年呢?
- 考察1个月,这个月好,下个月不好,到底销售员的表现算不算好?
- 考察3个月,是考察总量、平均值,还是单月达标次数?
- 考察6个月,若销售员稳定性好,则业绩越来越好;若销售员为先好后差的,那么业绩要不要作区分?
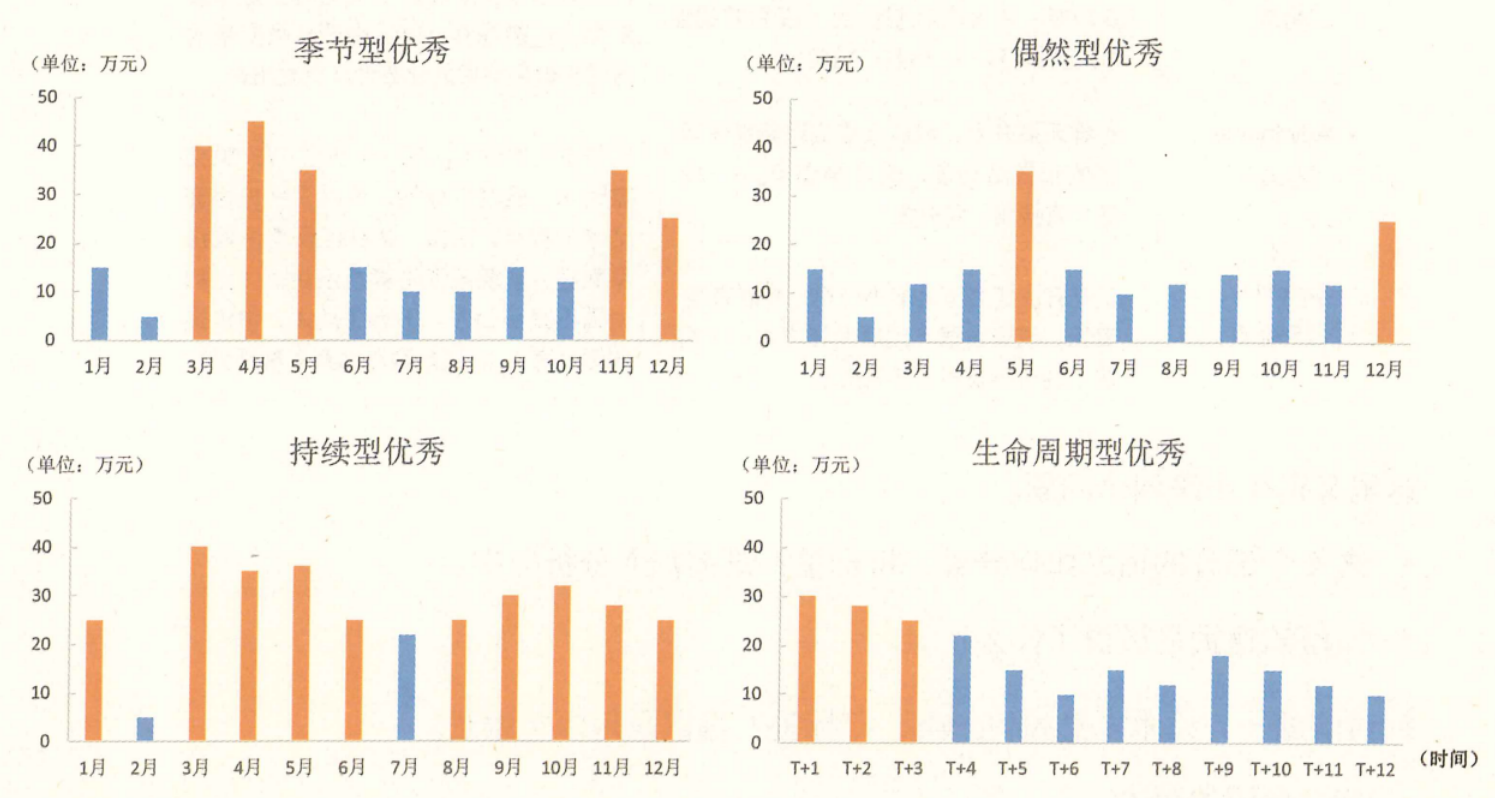
即使只关注一个指标,比如销售业绩。不同的销售员,也可能有不同的走势,其差异之大甚至可能直接影响到整体策略。比如,销售员的业绩,是季节性优秀/偶然性优秀/持续性优秀,说明话术可能不是成功的关键,抓队伍建设才是重点。如果是生命周期型,就证明培育旧用户没有用,需要源源不断地招募新人,这些基础的分析,直接影响后续方法的选择(见下图)。
以上所有问题的处理,都是为了得出一个简单的业务员分级标签。
同样的问题,在分析客户那里也存在,也很让人纠结。比如评定客户等级。
- 考察哪些指标?
- 考察多长时间?
- 指标到什么水平算好?
- 考察期波动怎么处理?
- 在未签约前要不要做预测?怎么预测?
- 要不要在签约进度中修正预测?怎么修正?
都分析清楚了才能有准确的客户评级,特别是售前评级。
正是因为以上工作太过纠结,所以衍生出3种常见的处理办法。
- 从简单到复杂:先做单指标分类,再慢慢增加,迭代几次。
- 先抓典型再总结:比如先让业务方标注几个正样本,然后研究他们的特点。
- 从结果倒推:比如业务方的KPI是签约额,那为了达成这个目标,需要怎么做才行。
每一种方法都有各自的工作办法,这里就不一一展开了。只是为了让读者感受到想获取个准确的分类,需要投入人力、物力和财力,不然就只能做最简单的、充满BUG的分析。
然而,就算这样依然不够,配合第一层地基的是第二层地基。
3.技术支持之二:业务分类与业务标签
A话术这个分类又是怎么来的?
实际上销售员卖东西时很少只说一句话,特别是toB类销售员,他们前前后后需要介绍很多,这里至少有4个部分。
- 开场问候:开场寒暄,引入话题。
- 产品介绍:主动介绍产品的特点、优势,以及对客户的用处(见下图)。
- 问题答疑:针对客户的问题,解答客户的疑惑。
- 促单话术:催着客户赶紧下单。

这里又衍生出来两个问题。
- 这4个部分的话术如何分类、打标签?进而加入分析之中。
- 如何知道销售员说了什么?
针对问题一,话术本身如何分类、打标签?可以采用以下做法。
- 产品介绍的版本。
- 客户问题点:功能、价格、体验、案例、系统接口。
- 促单的话术分类:按项目进度、优惠、资源控制。
总之,有了这些扎实的基础工作,才能有最初的A话术这个分类标签。这个看似简单的标签实则凝聚了大量的工作。 然而,这还只是第二层地基,还需要有第三层地基。
4.技术支持之三:基础数据采集
针对问题二,核心在于数据怎么采集。
- 如果有SCRM系统,那么交易流程可以系统化实现,即在一定程度上补足数据,比如展示了哪些案例(产品介绍环节),调用了哪些资料(问答环节),查询了哪些优惠(促单环节)。
- 如果没有系统的支持,那就只能从其他行为反推,比如销售培训、销售策略;比如申请体验样品类型、数量;比如申请优惠。
那么,又衍生出下面的问题。
- 销售培训记录,培训类型标签库。
- 销售策略记录,策略分类标签库。
- 申请样品记录,申请类型标签库。
- 价格申请记录,产品价格折扣标签库。
没有这些记录和标签,整个销售过程处于失控状态:一方面人们不知道做了什么,另一方面关联不到工作结果,根本无法深入分析。总之,一有记录,二有标签,这样分析起来才能得心应手。
如果孤立地看“怎么找一个好的话术”,似乎在地表建筑阶段就已经做得很完美了。可实际上,脱离了底层大量的地基建设,再华丽的地表建筑也盖不起来。整个流程串起来,就是用一个庞大的体系,解决了一点点业务上的问题。虽然工作量大,但是它真的有效,如下图所示。
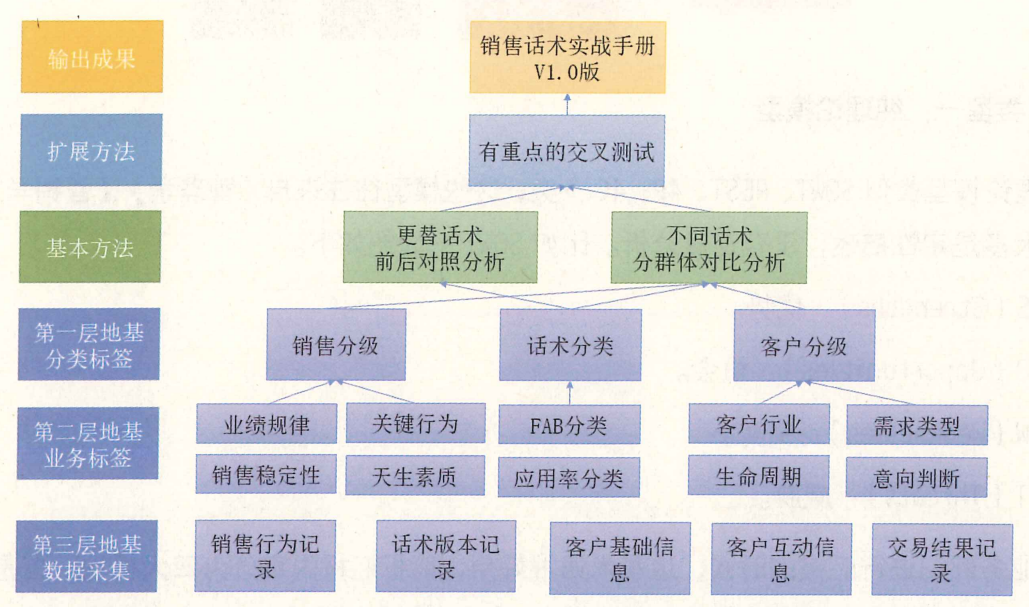
以上就是从基础数据采集,到标签制作,再到数据检验的全过程。即使如此简单的一个问题,也需要大量的基础工作才能做得完美。如果想做出高级数据分析,那么基础工作越多越好,所谓“食不厌精、脍不厌细”正是这个道理。
高级方法与算法模型
很多人会习惯地把高级方法等同于模型,似乎只要用了模型就很高级。可是在企业内不同部门的人口中,模型的含义是不一样的。广义上讲,只要是对现实问题的抽象,都可以叫模型。但狭义上讲,只有统计学、运筹学、机器学习等用到了数学公式的才能算模型。下面系统盘点一下,到底有多少种模型的说法,以及这些模型与高级方法之间有何种关系。
下图所示的五大类共九小类方法,都会被不同的人称为模型。
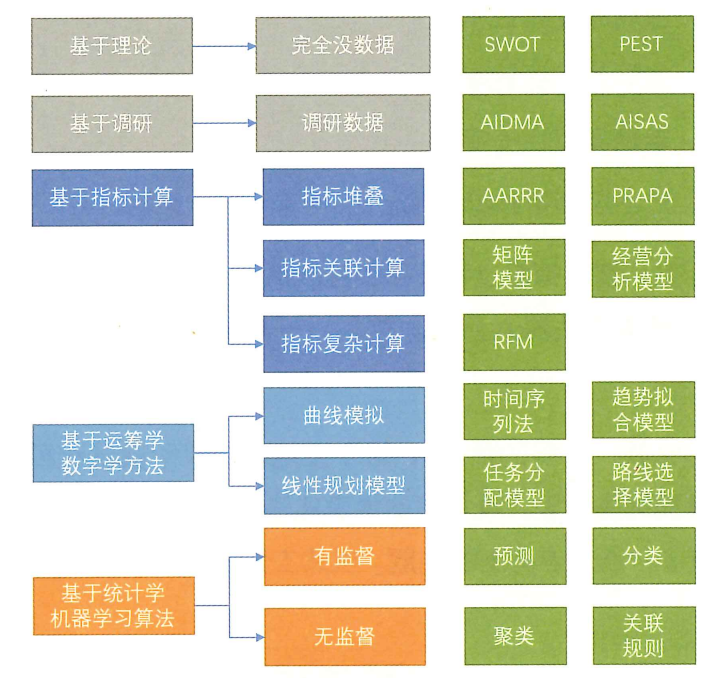
1.类型一:纯理论模型
纯理论模型类似SOWT、PEST、4P、4C一类,这些模型往往来自《管理学》《营销学》课程其内容大多是定性描述,没有定量分析。比如SOWT的介绍如下。
- S(Strengths):优势。
- O(Opportunities):机会。
- W(Weaknesses):劣势。
- T(Threats):威胁。
在业务部门进行汇报的时候,这些术语很好用,能把汇报内容分为四大模块。但是真要量化分析,比如“我们的产品到底为业绩带来了多少亿元的优势”“我们的品牌不足又降低了多少亿元的业绩”,完全无法量化进行。其他的,如4P、4C、PEST的分析也是类似的。
所以严格来说,这些不能算数据分析模型,只是一个思考方式和分析方向。大部分情况下是做纯业务汇报,只有少数有可量化指标的时候才能做量化分析。比如PEST中的P(Politica1),即政策。如果有政策限制,要求下架一些不合规的产品,则可以通过这些不合规的产品的销量,来分析政策的影响。
2.类型二:基于调研数据的模型
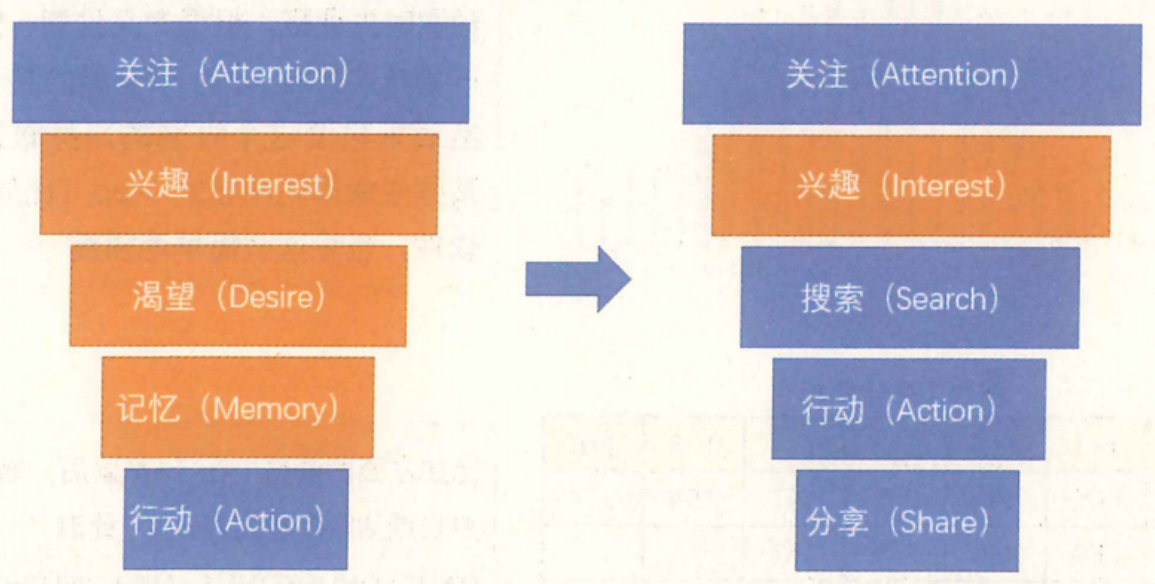
调研数据的模型类似AIDMA、AISAS、PSM模型。这些模型是经典的营销分析模型,之所以经典,是因为它们大部分基于调研数据,如用户态度、感觉、评价,是基于传统调研的手段获取数据的。在当下,能获取用户数据的方法很多,直接采用AB测试方法,比通过问卷问态度再反推更直观,因此这些模型适用范围已大大缩水。从理论上看这些模型没有问题,但是直接运用的话,其运用范围很有限。
为了体现自己的价值,调研公司、咨询公司、广告公司还是很喜欢介绍这一类模型的,毕竟用户没有开数据接口,行为数据记录再多,还是不能直接推导出用户的想法的。为了让这些模型能和现有数据结合,有些调研公司对模型进行了更改。如下图所示,仅用调研解决用户兴趣问题,其他环节则替换成可记录的数据。因此在产品经理、运营人员、研发人员对用户需求很迷惑的时候,还是会求助于市场调研,从而用到这些模型。
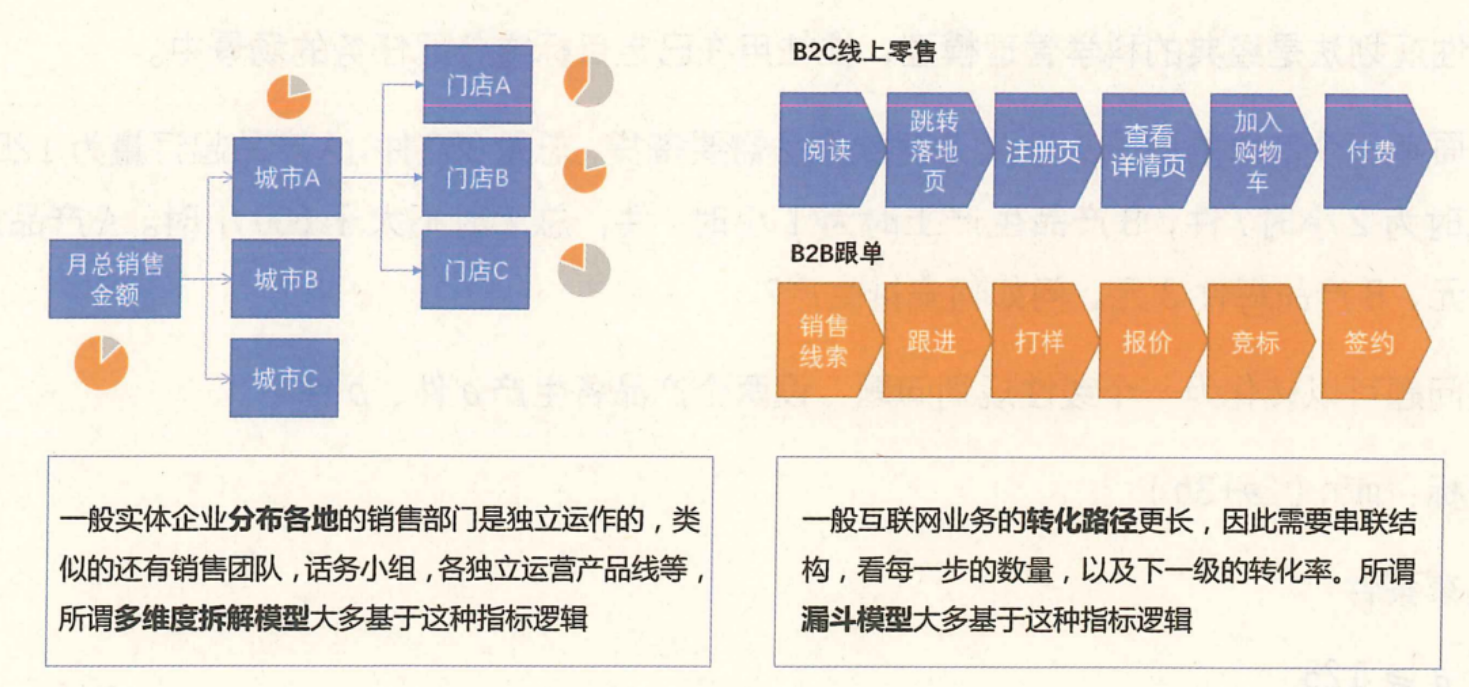
3.类型三:指标计算模型
指标计算模型类似AARRR、RFM 这些模型。这些模型才是业务员提及率最高的,介绍得最多的模型。这些模型往往直接使用业务部门的KPI指标,以有逻辑的方式呈现,因此业务部门在讨论问题的时候可以直接往里边套数据,非常好用(见下图)。同时,这些模型都是可以基于指标继续拆解的,因此业务讨论完了,可以直接按小组分配任务,并且监督任务的完成情况。这两项优势,使得业务员非常喜欢用这一类模型,时不时还可以自己创造两个。
但是,这一类模型有一个致命的缺点,就是关键参数来自经验,未来预测全凭“拍脑袋”。
当问业务员“为什么估计转化率是20%”时,得到的回答不是“最近几个月都是20%”,就是“我觉得它会是20%”。
因此,这些模型更适合展示现状,分析过往数据,不太适合对未来进行预测。
4.类型四:指标计算模型
指标计算模型类似曲线拟合法、时间序列法、线性规划法构造出的模型(见下图)。
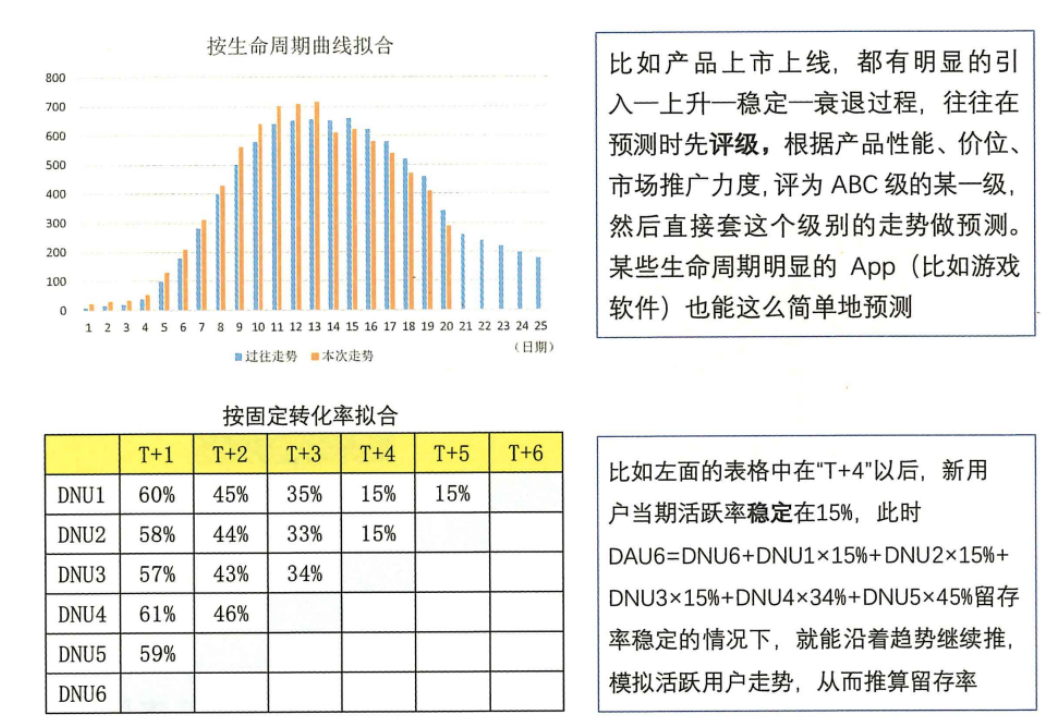
曲线拟合法一般用来预测整体指标走势,比如整体销量、整体产品数量、用户流失数量等。这种做法简单、粗暴、不看原因、只看结果,拿结果数据的过往走势,拟合未来走势。虽然看起来粗暴,但是非常好用。因为需要的数据量少!只有一个结果数据即可。很多情况下,简单省事就是王道,因此适用范围非常广。
线性规划法是经典的科学管理模型,往往用在已定目标或分配任务的场景中。
下面举一个简单的例子:有A、B两款产品需要备货,总量350件,A产品起订量为125件生产工时为2小时/件,B产品生产工时为1小时/件,总工时不大于600小时。A产品成本每件2元,B产品每件3元,问如何安排生产?
该问题可以转化为一个线性规划问题:设两个产品各生产a件、b件
目标:min(2a+3b)
约束条件:
- a > 125
- a + b > 350
- 2a + b < 600
- a ÷ b > 0
之后求解该线性规划模型即可得到答案。
理论上,线性规划方法在生产、库存、运输、采购等领域有广泛的应用。但实际上,在国内企业的应用很有限,只有少数供应链复杂的大型企业有研究。其中最大的制约来自基础数据的积累:线性规划方法,需要对供应链的生产力、运力、人力、执行力有长期的数据监控与积累才能沉淀稳定的数据。而在现实中,大部分企业供应链管理粗放,他们往往更喜欢用突击加班增加外包等方式应对,数据积累少。在营销端更是如此,规划方案往往依赖领导层“拍脑袋缺少数据积累,当然无法做量化分析。”
5.类型五:算法模型
算法模型类似LR、KNN、xgboost、SVM一类的模型。
近几年特别火热的机器学习算法和传统的统计模型,都是算法模型,也是狭义的“模型含义。但是,这些算法大部分不是用来解决企业经营问题的,而是应用在工业中,比如安防、辅助驾驶、语音识别、语音控制、内容推荐、商品推荐、反欺诈、风控等。这些都是生产系统非数据分析/BI系统。在架构上一般都是专门的算法组/风控模型组负责,不会和数据分析组重叠。
在企业经营方面,算法有一些经典的应用场景,比如响应率预测、消费能力预测等,但始终不是数据分析的工作重点。因为大部分企业经营场景面对的问题是“没数据!”采集数据整理数据、分析数据才是数据分析组的主要任务。且大部分算法理解性差,业务员既无法参与也无法理解,因此能输出的成果非常有效,从而限制了算法在分析上的使用。
多个模型如何在企业实际运用呢?举个简单的例子,比如预测12月的销量,那么可以参照下表来进行。

这样直观对比就能看出来,为什么统计学/机器学习算法模型,在实际场景中运用很少了。
这些模型需要的数据多,需要的数据颗粒度细,建模过程复杂,输出的结果反而更简单,业务员看了能做的事也少。
相比之下,套用经营分析的模型进行拆解,虽然主要参数都是“拍脑袋”,但也变相地给各个部门下了军令状:“你必须做到这么多!”这样更容易驱动业务部门行动。用时间序列法虽然算出来的也不能落地,但是它需要的数据少,只有一串数据照样用,因此省事。
TIP
注意:
- 上面的对比并不能说明机器学习方法不适合经营分析,只是场景不合适而已。换个场景用,比如用二分类模型预测用户购买率,就有两种典型好用的用法。
- 在响应率低的时候,压缩业务工作量,提高产出率。最典型的就是外呼,用户如果不接电话,任凭外呼员巧舌如簧也没用。并且外呼成功率特别低,自然成功率只有1.5%~2%,因此哪怕模型只提高一个点的接听率,也能让外呼员的效率提高一大截。
- 在响应率高的时候,识别自然响应群体,减少投入。最典型的就是营销成本控制。如果想压缩优惠券投放,最好的办法就是预测人们是否购买,之后把购买概率高的群体的优惠券去掉。对于释放费用,非常好使。
所以在工作中,复杂性不代表正确,更不代表有用。根据以下维度,才是发挥作用、争取认可的好做法。毕竟企业工作,追求的是低成本高效率地解决问题,如果一味追求复杂尖端,效果并不好。
- 数据丰富程度。
- 数据质量高低。
- 结果使用场景。
- 期望上线时间。
但反过来说,套上一个模型的外壳,的确能让分析显得高级很多。所以可以根据这5类模型的特点,把自己的工作也对应套上模型的光环,瞬间可以增加高级感。